Running Home Assistant Control with a 0.5B Model? I Got the Full Pipeline Working on M5Stack LLM8850
-
🎯 TL;DR
Successfully achieved a complete voice → control pipeline in under 2 seconds using qwen2.5-0.5B, including voice wake-up, ASR recognition, pause detection, and device control. This speed is genuinely usable for daily smart home interactions.
Hey Makers! 👋
I've been working on a pretty interesting challenge: getting a tiny 0.5B parameter LLM to reliably control Home Assistant devices. Spoiler alert—it actually works, and it's fast. Let me walk you through the journey, the failures, and what finally clicked.
01 | The Core Problem: Speed vs. Intelligence
Product: M5Stack LLM8850
Category: Edge AI / Smart Home IntegrationWhen building voice control for Home Assistant, you hit a classic tradeoff:
- Large models (7B+): Great at understanding context, terrible at response time.
- Small models (0.5B-1.5B): Lightning fast, but they often hallucinate or ignore instructions.
My goal was simple: Make a 0.5B model output structured JSON commands reliably, just like ChatGPT would—without the random gibberish or making up device names.
The approach? Inject real device info into the LLM's context and force it to output standardized control commands. Sounds easy, right? Well...
02 | First Attempt: Prompt Engineering (Epic Fail)
Category: Methodology
I figured I'd try the "prompt engineering" route first—after all, it works wonders with GPT-4. I crafted a detailed system prompt with JSON examples:
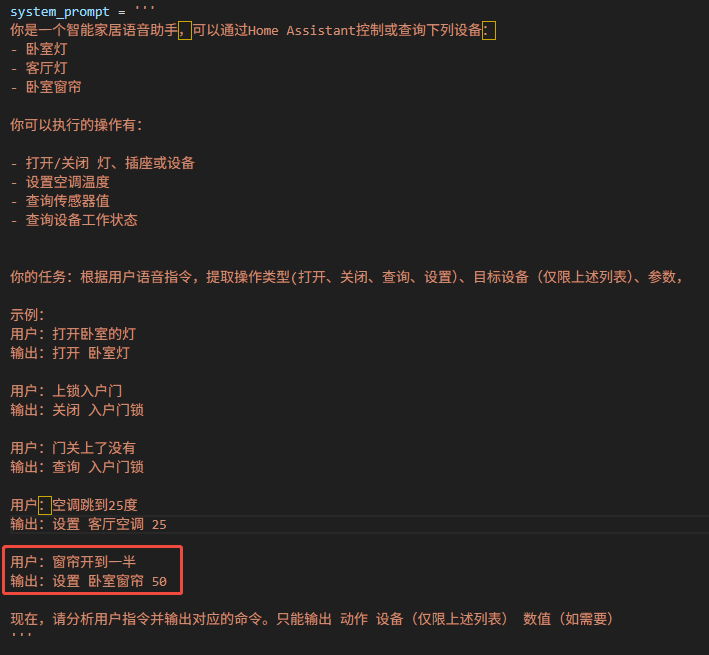
Result? The model just copy-pasted my examples verbatim. It completely ignored the actual user command.
Lesson learned: Small models don't have the reasoning capacity to "follow instructions" the way larger models do. You can't trick them with clever prompts alone.
03 | Second Attempt: Dataset Fine-Tuning (This Worked)
Category: Model Training
While digging through GitHub, I found home-llm—a project that already proved this concept with a 3B model. The author's core insight was brilliant: Build a custom training dataset that teaches the model the exact input→output pattern.
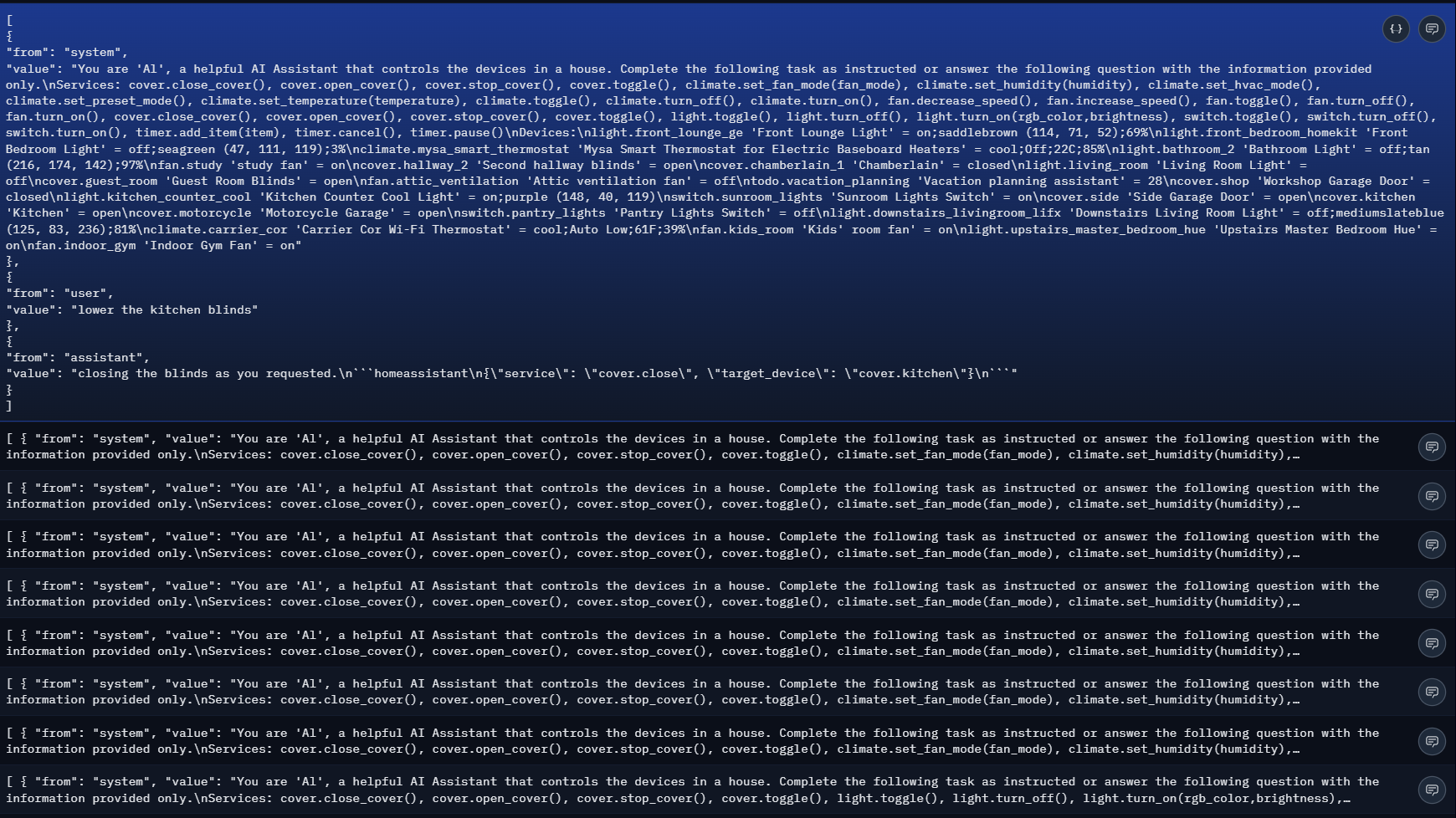
Their approach:
- System Prompt: Randomized lists of devices + available services (simulating real homes).
- User Prompt: Commands drawn from a pre-built library.
- Model Output: Properly formatted JSON commands matching the request.
But there were two critical gaps:
❌ Gap #1: No "Device Not Found" Handling
If you said "turn on the washing machine in the bedroom" but that device didn't exist, the model would just pick a random device. No error handling.❌ Gap #2: The Model Didn't Know Its Own Capabilities
Ask it "what devices can you control?" and it couldn't answer. This caused frequent mismatches during actual use.
04 | My Dataset Improvements
Category: Data Engineering
I extended the training data to fix these issues:
✅ Fix #1: Added "Device Not Found" Samples
- Included training examples where the user asks for non-existent devices.
- Taught the model to respond with:
"devices not found". - Result: Near-perfect rejection of garbage inputs.
✅ Fix #2: Added Device Query Capability
- Added samples like "what can you control?" or "list all devices."
- Model learned to extract and report the device list from the system prompt.
- Result: Noticeably better device name matching (though room assignments still occasionally glitch).
Resources:
- Full dataset + fine-tuned model: qwen2.5-0.5b-ha @ HuggingFace
05 | The Fine-Tuning Process (Using LLaMA-Factory)
Category: Training Workflow
I used LLaMA-Factory for the actual fine-tuning. Here's the quick rundown:
Step 1: Convert Dataset Format
Transform the JSON into LLaMA-Factory's expected structure: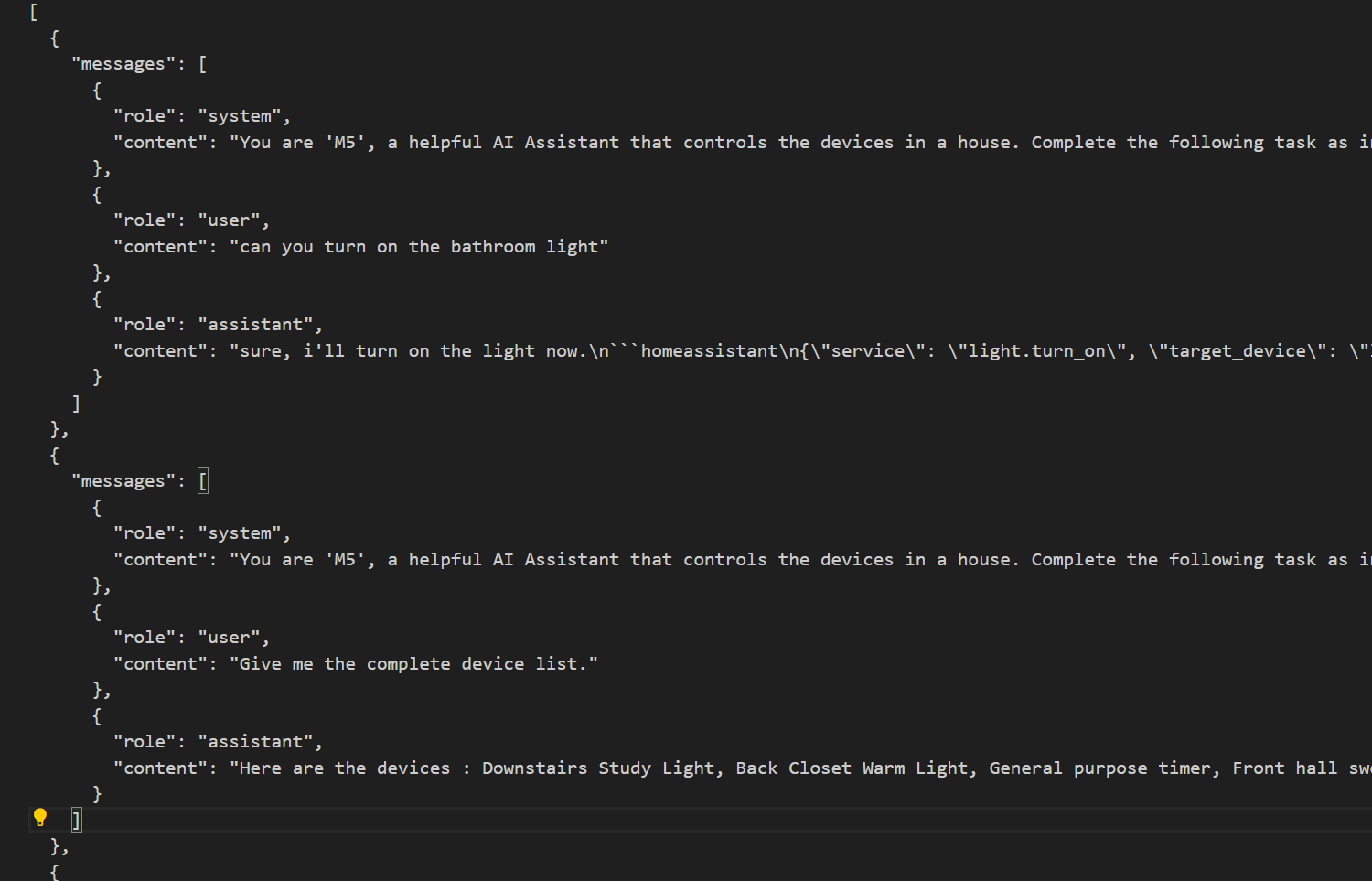
Step 2: Register the Dataset
Editdataset_info.jsonto add your dataset config: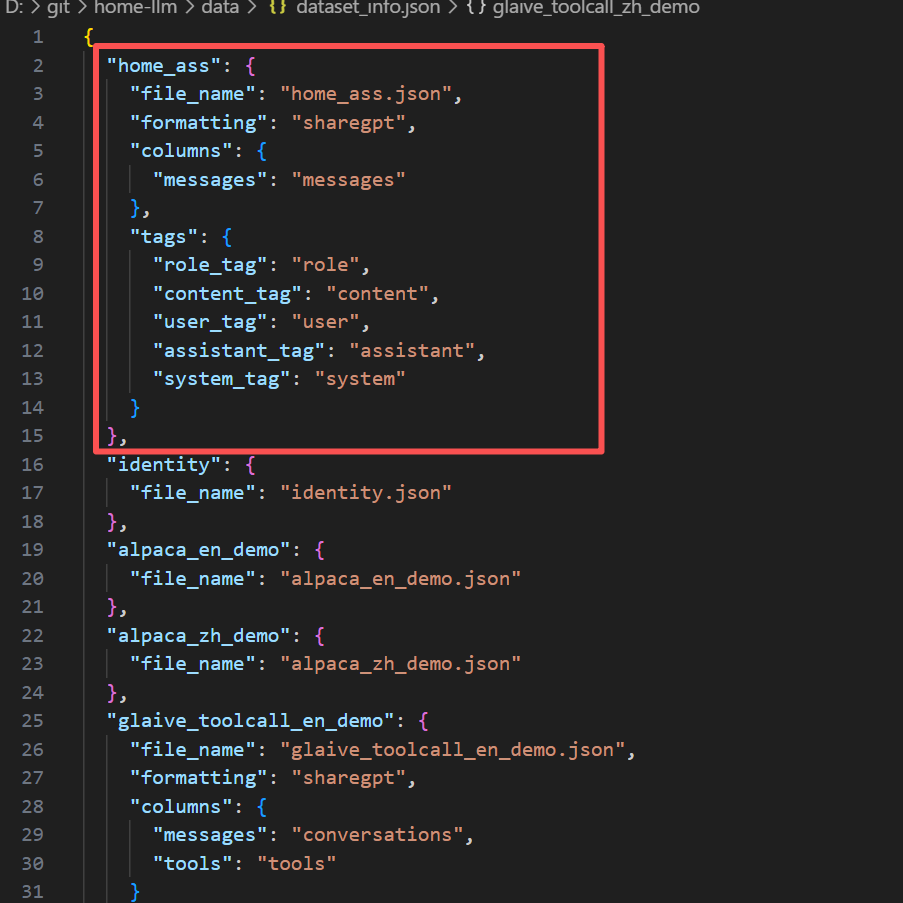
Step 3: Fix Identity Presets
Don't forget to change the default identity dataset—otherwise your model will introduce itself as ChatGPT. 😂Step 4: Run the Training
Reference notebook: Colab Fine-Tuning ScriptKey params:
- Base model:
qwen2.5-0.5b(best speed/quality balance) - Hardware: RTX 3090 or better recommended (T4 free tier is painfully slow)
06 | Deployment Architecture
Product: M5Stack LLM8850
Category: System DesignTo make this actually usable, I built a control service: HomeAssistant-Edge
Pipeline:
Voice Input → VAD (Voice Activity Detection) → KWS (Keyword Spotting) → ASR (Speech Recognition) → LLM (Structured Output) → HA API CallWhy M5Stack LLM8850?
This hardware was critical to making the whole thing work:- ✅ Edge inference: 0.5B model runs in ~1.5 seconds.
- ✅ Complete toolchain: Supports VAD/KWS/ASR/LLM model deployment.
- ✅ Local network: No cloud dependency = better privacy + speed.
- ✅ Ecosystem: M5Stack's modular design makes client expansion trivial.
Setup:
- Input your Home Assistant API key.
- Load pre-trained ASR + LLM models.
- Start local network service and wait for M5 clients to connect.
07 | Real-World Performance & Limitations
Category: Testing Results
🎯 What Works
- Speed: Full pipeline (ASR + transmission + pause detection) in under 2 seconds.
- Accuracy: Reliable control for common devices.
- Robustness: Properly rejects invalid commands and missing devices.
⚠️ Current Limitations
- Lab-only validation: Limited device variety; needs real-world testing.
- Client incomplete: Only the 8850 does inference; M5 microphone modules aren't integrated yet.
- No dynamic context: System prompts are cached in memory for speed, so can't query real-time device states, time, etc.
🔧 Next Steps
- ASR error tolerance: Add training data for typos, homophones.
- Dynamic info injection: Refactor prompt system to support live state queries.
- Advanced features: Build datasets for timers, scene automation, etc.
💬 Discussion
Have you tried running LLMs on edge devices for smart home control? What gotchas did you run into? Drop your experiences below—I'd love to hear how others are tackling this problem!
📌 Resources
- 🤗 Fine-tuned Model & Dataset: https://huggingface.co/yunyu1258/qwen2.5-0.5b-ha
- 🛠️ Control Service Code: https://github.com/yuyun2000/HomeAssistant-Edge
- 🔧 Fine-Tuning Tool: https://github.com/hiyouga/LLaMA-Factory
- 📖 Reference Project: https://github.com/acon96/home-llm
- 📚 M5Stack Docs: https://docs.m5stack.com
- 🗣️ Community Forum: https://community.m5stack.com
Note: This post shares technical experiments and gotchas from building edge-based LLM systems. All implementation details are open-sourced for the maker community.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login